
One of travel.cloud’s values that is particularly pertinent to the engineering team is, "Just because it works, doesn't mean it’s good enough". We live this value daily, constantly reviewing each other’s work and building a stronger software product, together, through feedback and improvement. There will always be new technologies that could make the platform stronger, we have to keep up with changes and trends and see if they would be good candidates for inclusion in future releases.
In recent weeks, some of the engineering team have taken time out from delivery to look at some of these new and emerging technologies. One such technology, and the subject of this post, is machine learning.
What is machine learning?
Machine learning covers the branch of IT where computers create predictions based on observations and success of past predictions. A machine's ability to learn is controlled by one or more algorithms which are used to build a model from an input observation set. This model is then used with other algorithms to enable data-driven predictions to be made, rather than following static outcomes or making random guesses.
Machine learning has been a perennial hot topic in IT as each new development within the industry pushes us ever closer to machines acting with true autonomy. The latest innovation that is making machine learning popular again is the vast amount of compute power that is easily available to anybody. In previous years only universities with Beowulf clusters and government organisations with supercomputers had the compute power to analyse a population sized dataset, and this would usually be an overnight batch job. Nowadays this amount of data can be processed using Amazon Web Services (AWS) for less than the cost of a cup of coffee and in less time than it takes to brew a cup of tea. Amazon Machine Learning (AML) builds on the availability of this power to offer a machine learning capability to AWS user, with a low barrier to entry.
The low cost of storage provided by cloud infrastructure means that most content providers are able to capture every click and request on their websites. This data is becoming training sets for machine learning. Whether you realise it or not, machine learning plays a part in everybody's online experience. Some common uses of machine learning are:
- Personalization: produce recommendations and optimize application use based on past purchases or browsing behaviour.
- Sentiment analysis: analyse text to classify it in some way e.g. working out if a product mention on Twitter was positive, negative or neutral.
- Demand forecasting: based on usage patterns ensuring there is enough power available at a given time.
- Fraud detection: identify activity like bust-out fraud and fraudulent changes to historic usage patterns.
Amazon has used machine learning for years, and the outputs of this are visible in the recommendations sections of your Amazon homepage. The items shown in the list aren’t just items purchased by other users who also purchased an item you purchased, they are the items the learning algorithm thinks you have the highest likelihood of buying based on your purchase history and other users’ purchase history. The subtlety in that difference could account for a reasonable increase in sales and given Amazon is worth $175.1 billion* they are obviously good at enticing customers to buy.
Amazon Machine Learning
Amazon Machine Learning builds on Amazon’s experience with machine learning and makes Amazon’s innovations and technology available to all.
AML can create models from three data sources currently but this list should grow as the technology matures. The types of data store that can be used with AML are:
- CSV files uploaded to an S3 bucket
- Redshift data warehouse
- MySQL using RDS
Even if native support isn’t available for a dataset at the moment, most stored data can be exported to CSV for use with AML.
After connection to the data source, AML analyses the content and makes guesses about the schema of the source data. The schema needs to be validated as the guesses are made from a sample of data meaning that a string field may be identified as date, or number as binary. Once the data source schema is set up, the data is statistically analysed for use in the model. Here is an an example of the output.
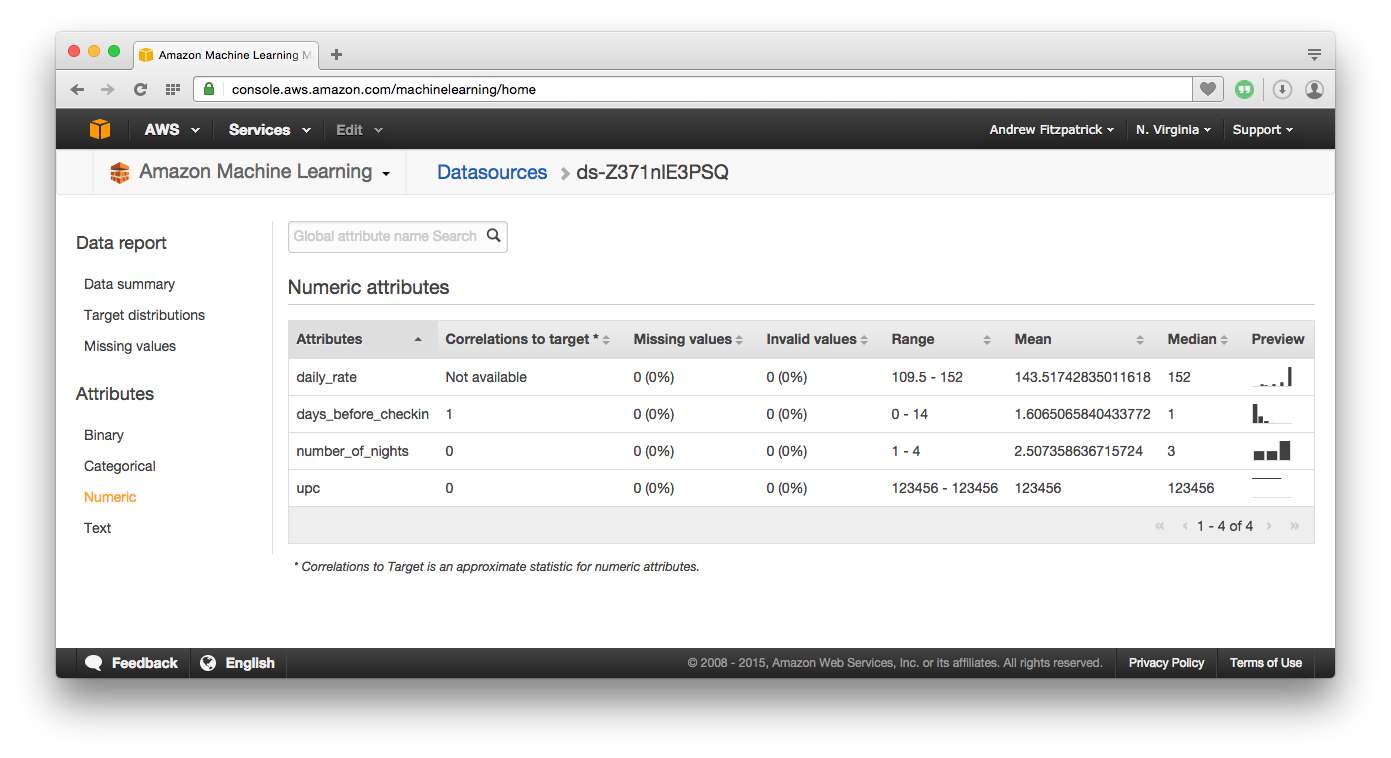
After the schema is defined, AML will build a model based on the schema and the type of output. The model will be one of three types, all of which are based on a numeric regression algorithm:
- Binary classification model: can predict 1 of 2 outcomes (yes/no) e.g. Is this email spam?
- Multiclass classification model: can predict one of more than 2 outcomes e.g. is this email positive, negative or neutral?
- Numerical regression model: can predict a value where the outcome is a number, e.g. predict the rate for a double room, in a given hotel, with a 4 night stay.
Part of building the model is to define an evaluation of the model, where AML uses a subset of the source data to test the predictions it makes and then tunes the algorithm. This could be a 70/30 split where the model is initially trained with 70% of the data and the remaining 30% used to test the model as it contains known outcomes. The test iterations help tune the model. The outcome of the build and evaluation is a report, for example:
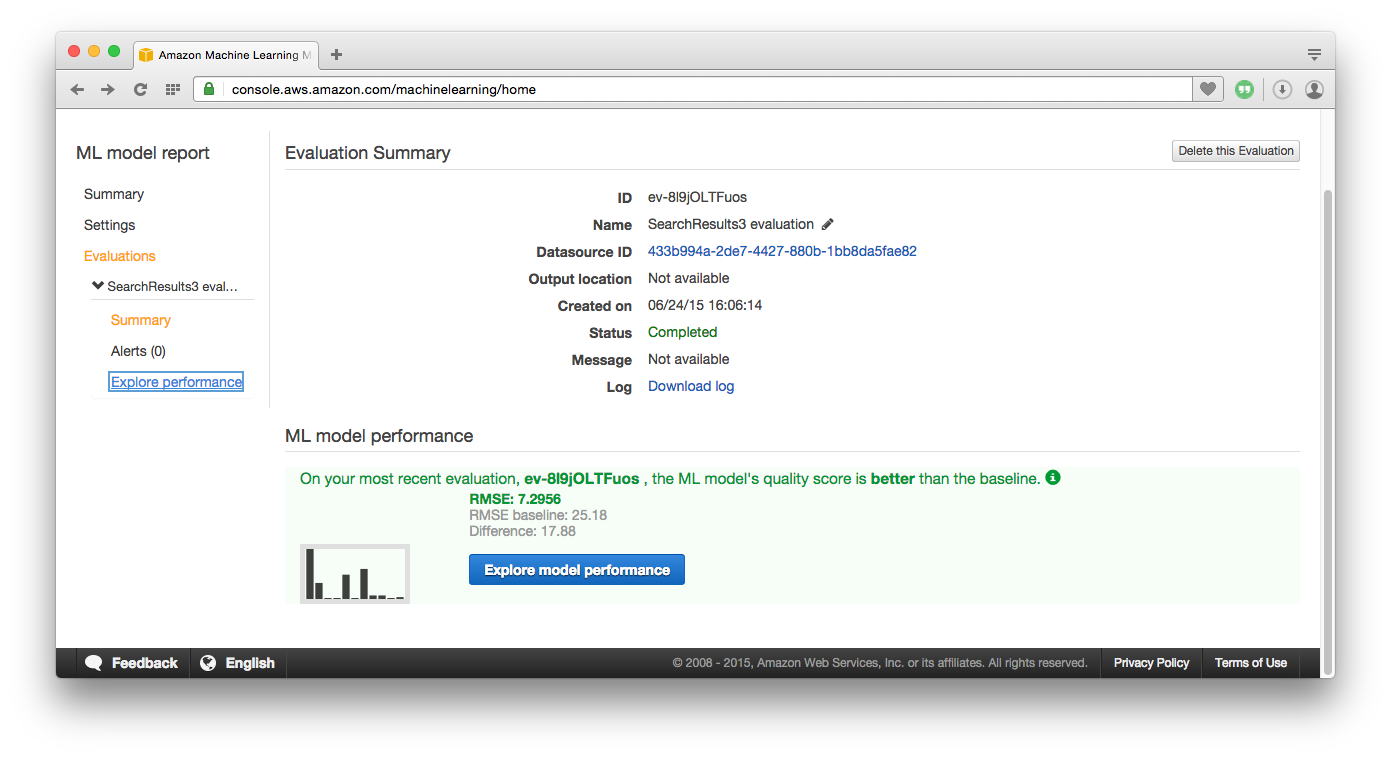
The Root Mean Square Error (RMSE) number shows how good the model is at predicting; the closer to zero, the better the model is. The baseline number given is the score for performing random guesses. The report above demonstrates that our model is better than random.The final part of the process is to choose whether the model will create batch or real-time predictions. Batch predictions will work on a whole dataset in one go and create an output file of corresponding outcomes, whereas real-time will look at one observation at a time and create a single prediction. There is a cost implication with using real-time processing, as throughput is higher - batch may be more desirable. As demonstrated above, with a few clicks and a basic understanding of machine learning, it’s possible to create a strong model that can make good predictions. This ease of use means those with the knowledge of the source data can create their models, rather than having to offload to a specialist.
Example
To test machine learning I created a hypothetical situation where the results of 2600 hotel searches are stored in the following way:
| id | search_date | check_in | check_out | daily_rate |
| 12345 | 2015-07-10 | 2015-07-11 | 2015-07-12 | 152 |
| 12345 | 2015-07-06 | 2015-07-11 | 2015-07-15 | 118 |
| 12345 | 2015-07-01 | 2015-07-11 | 2015-07-13 | 115 |
| ... | ... | ... | ... | ... |
This input is then processed into an input file for the machine learning model as follows:
| id | days_before_checkin | number_of_nights | daily_rate |
| 12345 | 1 | 1 | 152 |
| 12345 | 5 | 4 | 118 |
| 12345 | 10 | 2 | 115 |
| ... | ... | ... | ... |
The model was then built giving an RMSE rating of 7.2956. Real-time requests were made of the model to predict how much it might cost to stay in the given hotel if a guest wants to stay for a given number of nights and is making the booking a given number of days in advance. Here is an example of the outcomes from a number of searches to show how the predicted value vary depending on the input values:
| days_before_checkin | number_of_nights | predicted_value |
| 0 | 4 | 152.59 |
| 1 | 4 | 152.59 |
| 2 | 4 | 140.01 |
| 3 | 4 | 129.23 |
| 4 | 4 | 129.23 |
| 5 | 4 | 129.23 |
| ... | ... | ... |
The predictions were acceptable, as they mirrored the trend contained in the data but the predicted values were quite far off the input values, especially where the training set contained few observations. This was due to the data set I generated having deficiencies and I’d expect much better performance if a realistic, bigger, data was used to generate the model.
Potential uses
There are a number of use cases where using machine learning could be beneficial within our travel platform. Some that spring to mind are:
- Cache optimisation. As with the example, use historic searches performed and create predicted prices for product searches, rather than real prices to potentially speed up searching.
- Predicting hotel availability and issuing availability alerts. Machine learning could be used to blend historic availability with a list of known upcoming events to predict hotel availability around the times of the events e.g. how crufts affects hotel availability for business travellers. Travellers can then be alerted in good time if it looks like an event may impact on availability in their usual destinations.
- Search intent. Use machine learning to understand the intent the user had with their search by taking into account other factors like the organisation they work for and some personal details. For instance, someone on the graduate scheme in an organisation that searches for London may want to stay in a different hotel to a senior manager from the same organisation that performs the same search. Machine learning can be used to suggest the most desirable hotels for the user based on their profile.
All of the above can be used to help us work towards two of our other values, improving the customer's experience and to brighten their day.
*Correct at time of publishing.
Comments